Does Basque have an impossible phonological opposition?
01-02-2024
Glottal fricatives
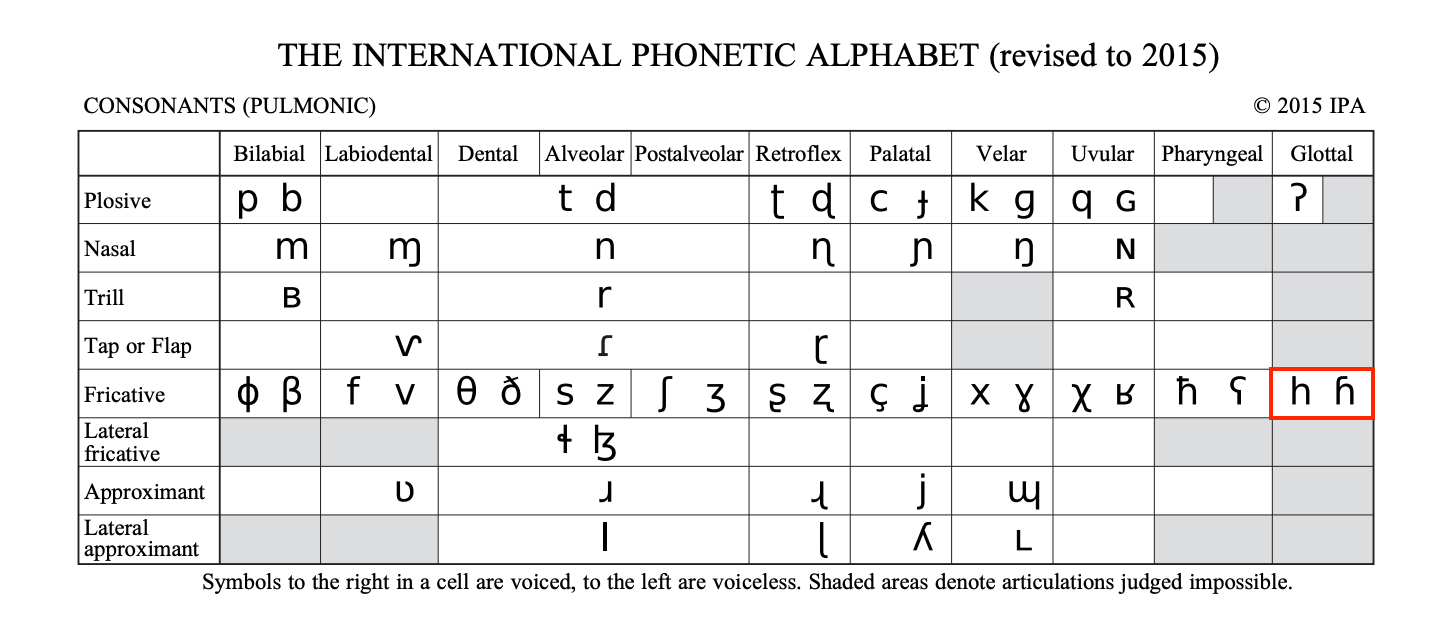
How about a nasalized glottal approximant /h̃/?
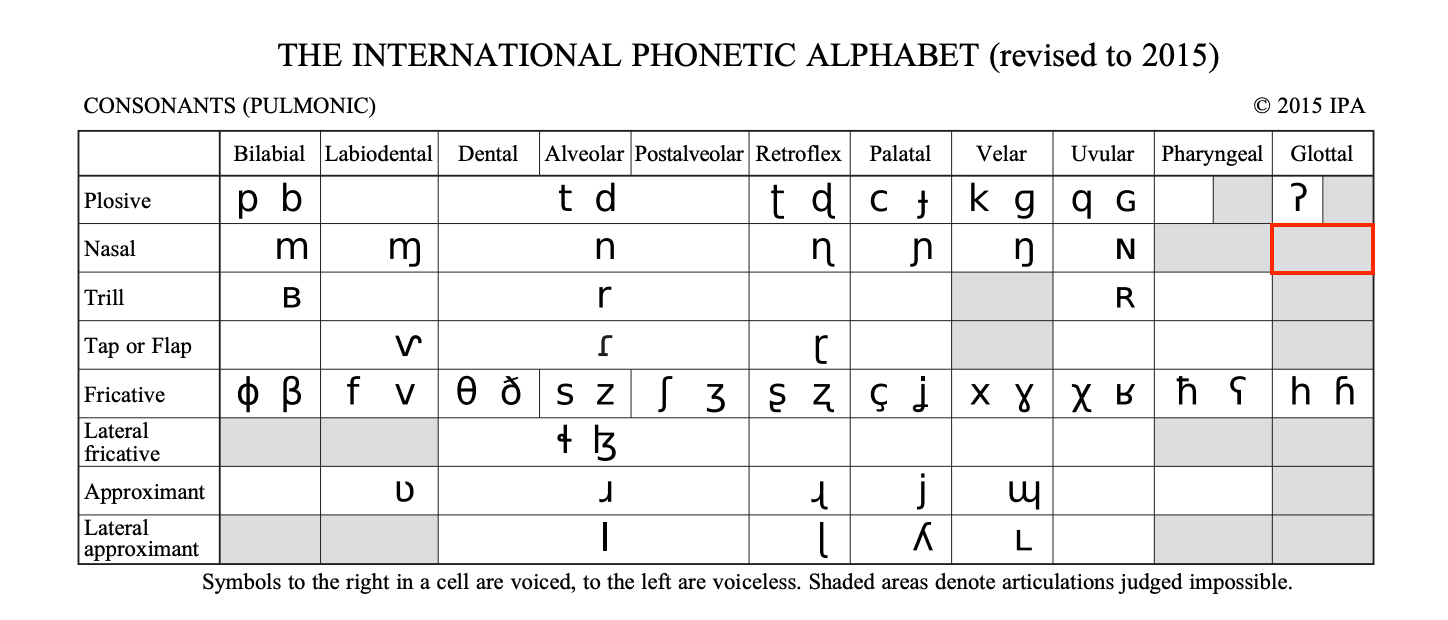
Zuberoan Basque
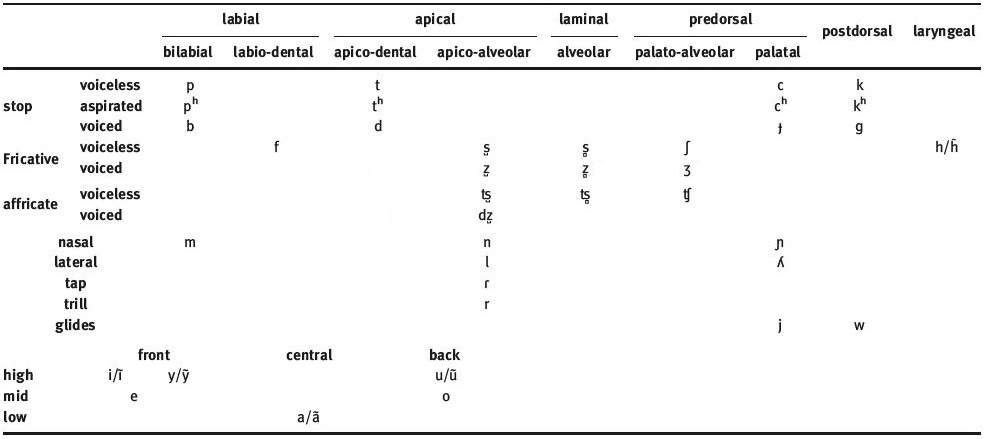
Let’s listen to them
Oral

Nasalized

Chronology

500-800 CE
Lenition of intervocalic /n/
/VnV/ > /Vh̃V/
1000-1300 CE
Loss of laryngeals
in post-tonic syllables
in Central-Eastern varieties
/hV.’hV.hV/ > /hV.hV.V/
Chronology
1600-1900 CE
Loss of nasality in aspirates
in most Basque varieties
/Vh̃V/ > /VhV/
Today
Nasalization of aspirates
preserved in Eastern Basque
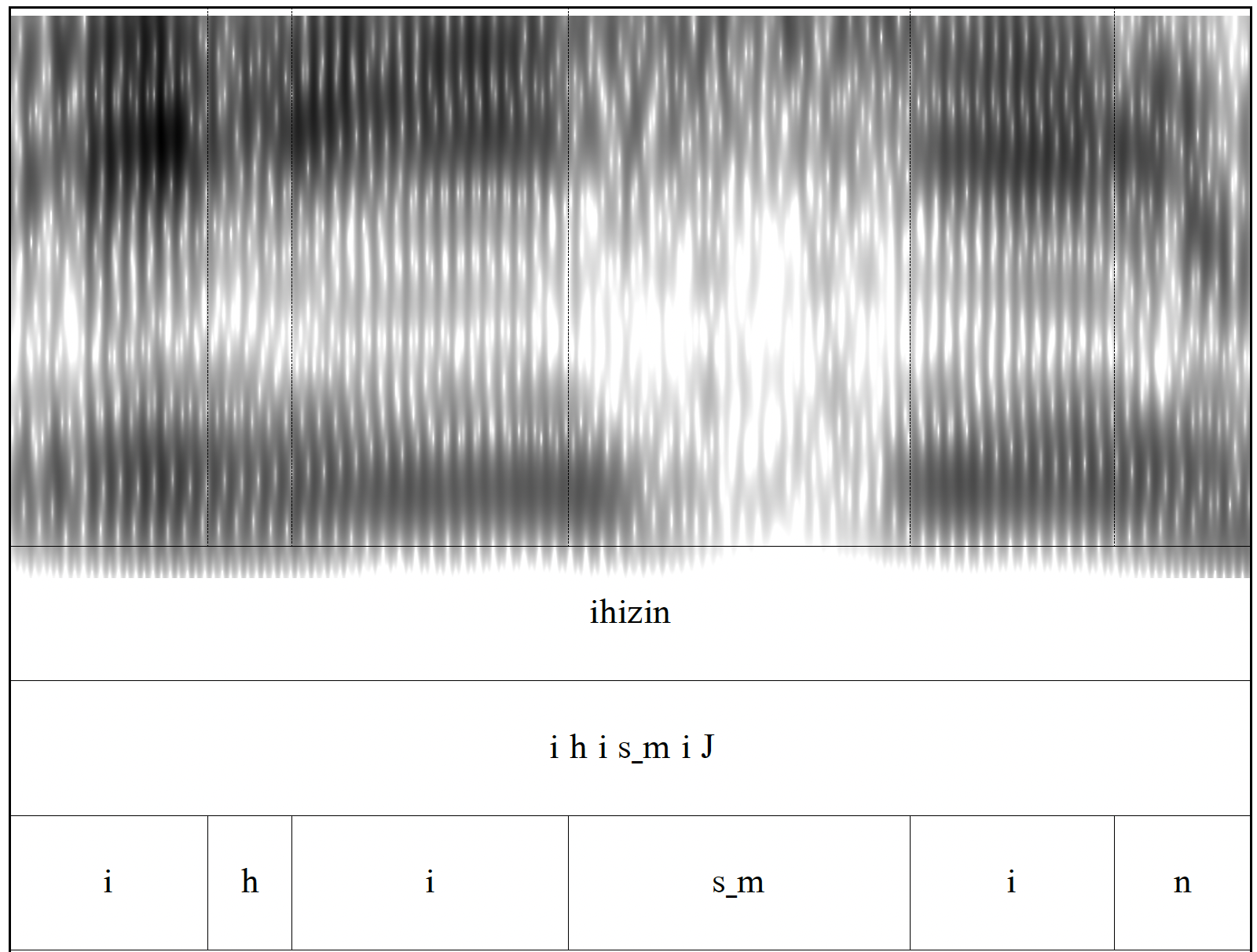
ehi ‘finger’ vs. eh̃i ‘easy’
Amiküze (Mixe)
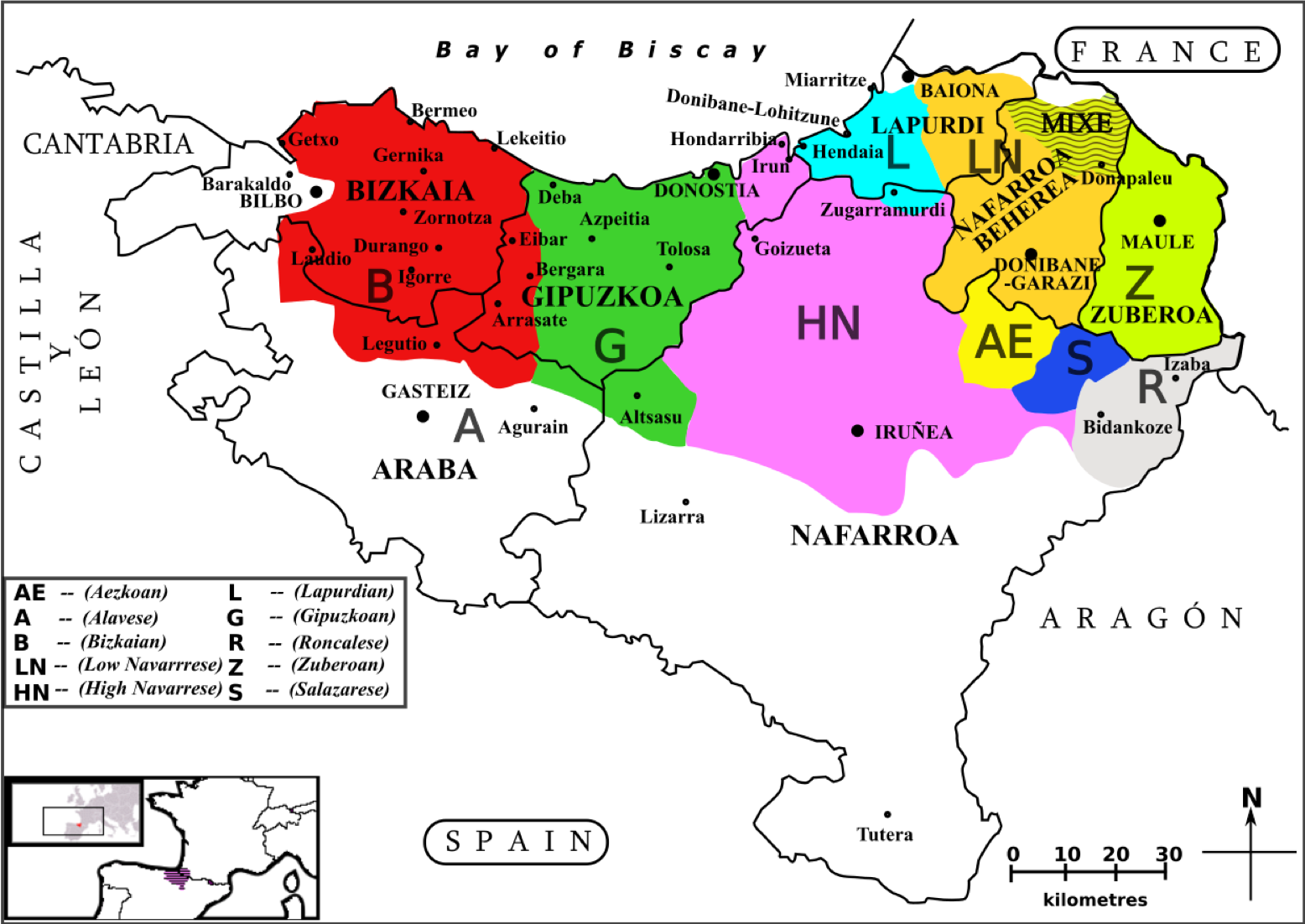
Materials


Data

Problem: Measuring acoustic nasality ![]()
SpeechRecorder: prompting

Nasalance device

Wooden plate


Recordings
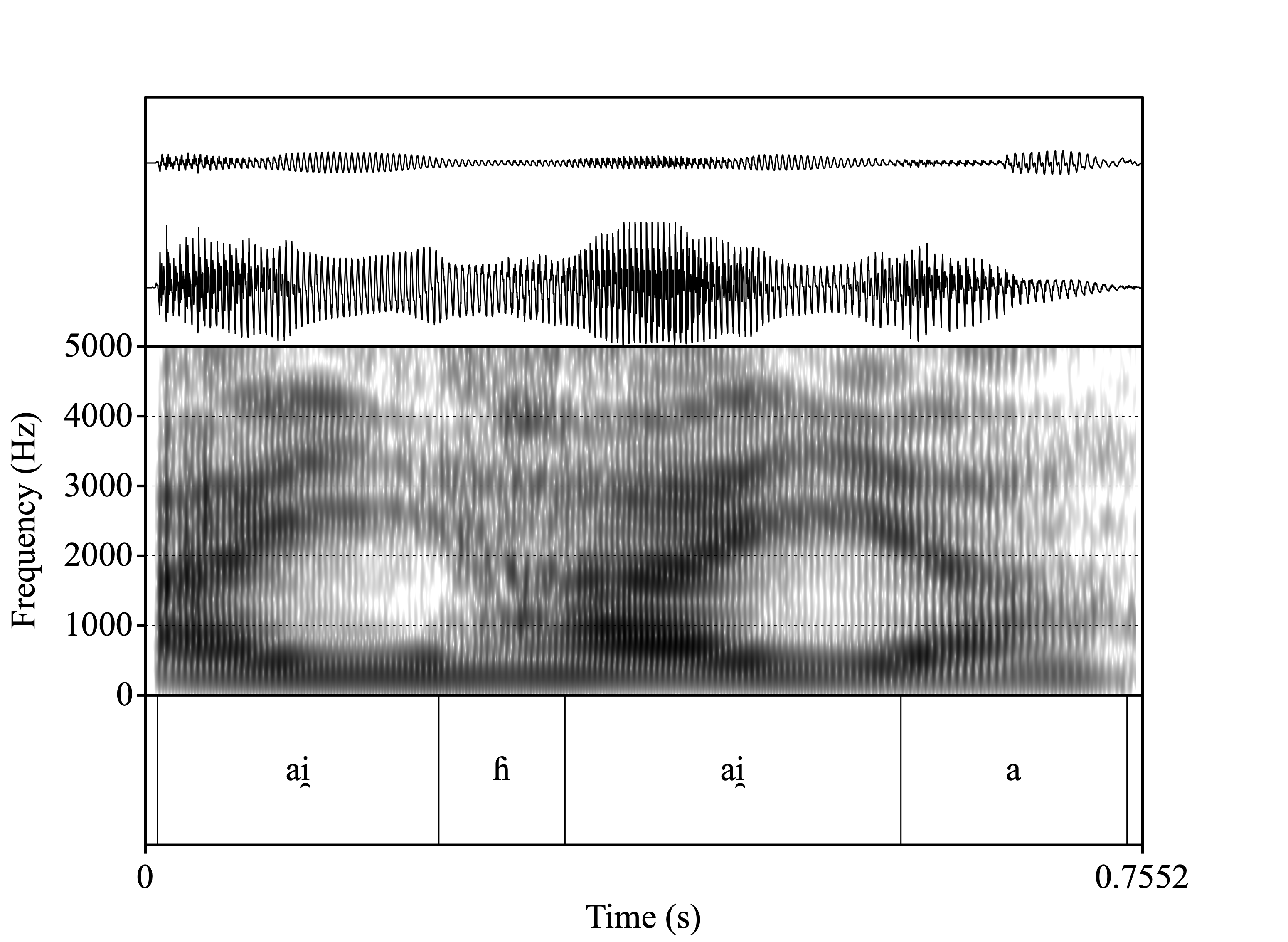
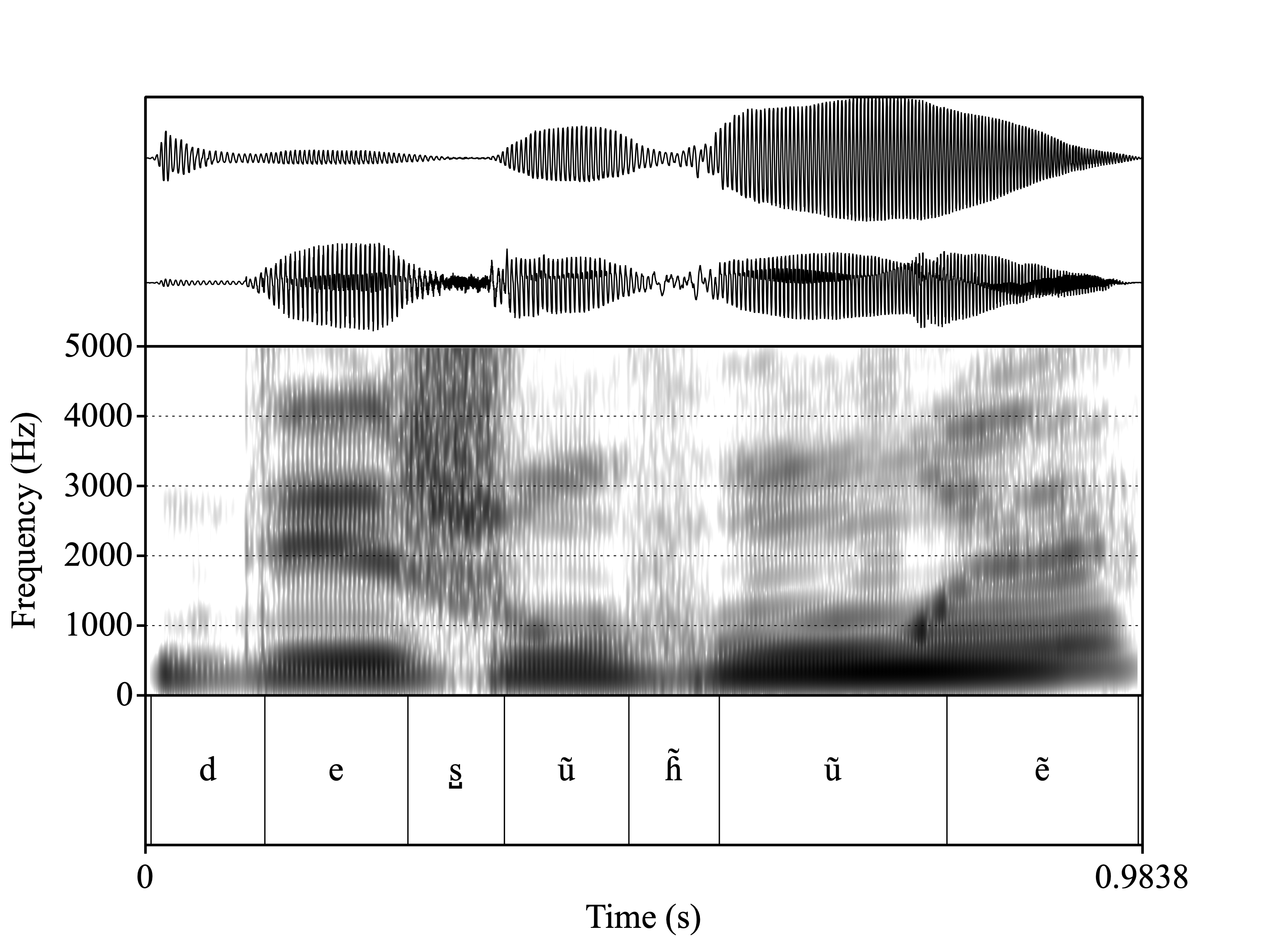
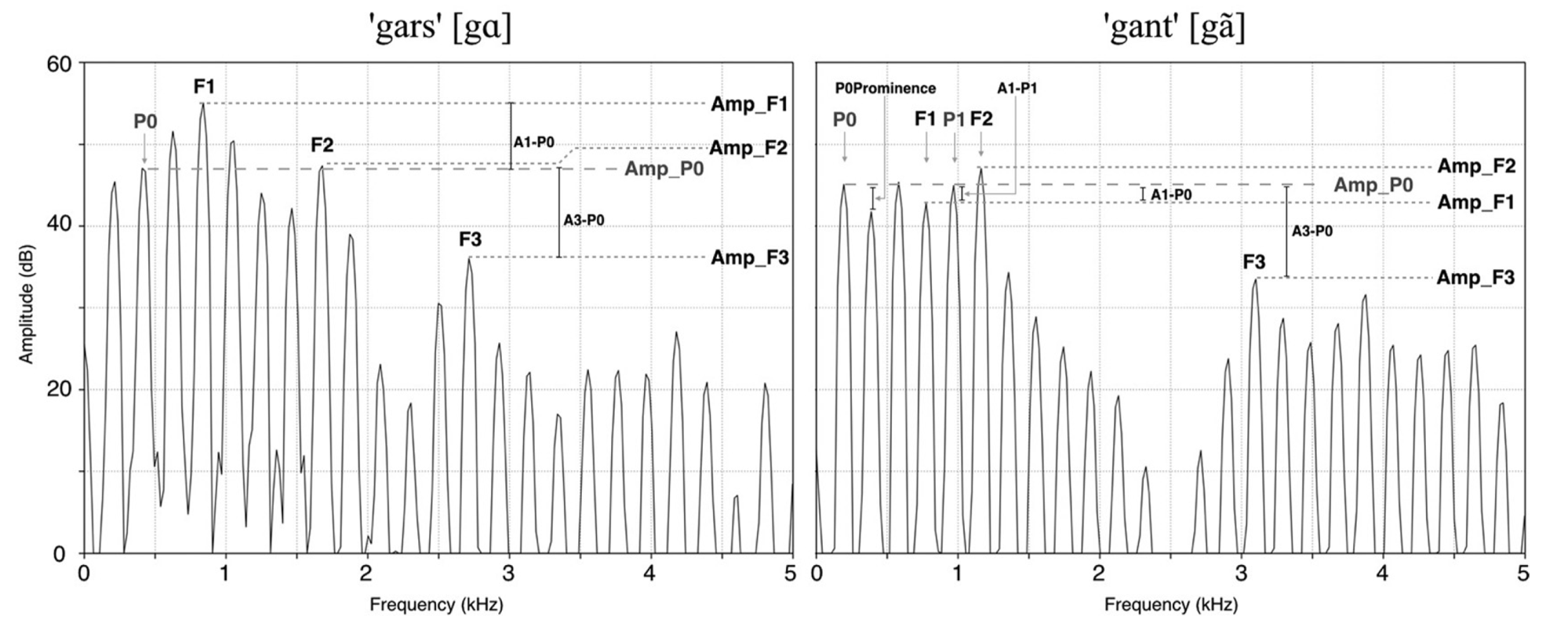
Nasalance
→
→
\[ Amplitude \]
→
→
\[ A_n \]
\[ A_o \]
↓
↓
\[ \frac{A_n}{A_n + A_o} \times 100 \]
Bayesian generalized hierarchical model with brms

Dependent variable: z-scored nasalance
Population-level predictors: aspirate category, trial
Group-level predictors: by-speaker correlated varying intercept & slope adjustments and by-word intercept adjustments
Weakly informative priors
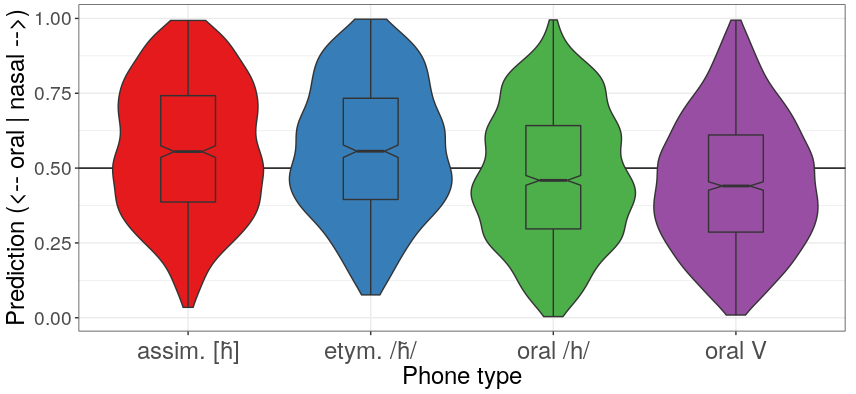
Posterior distributions
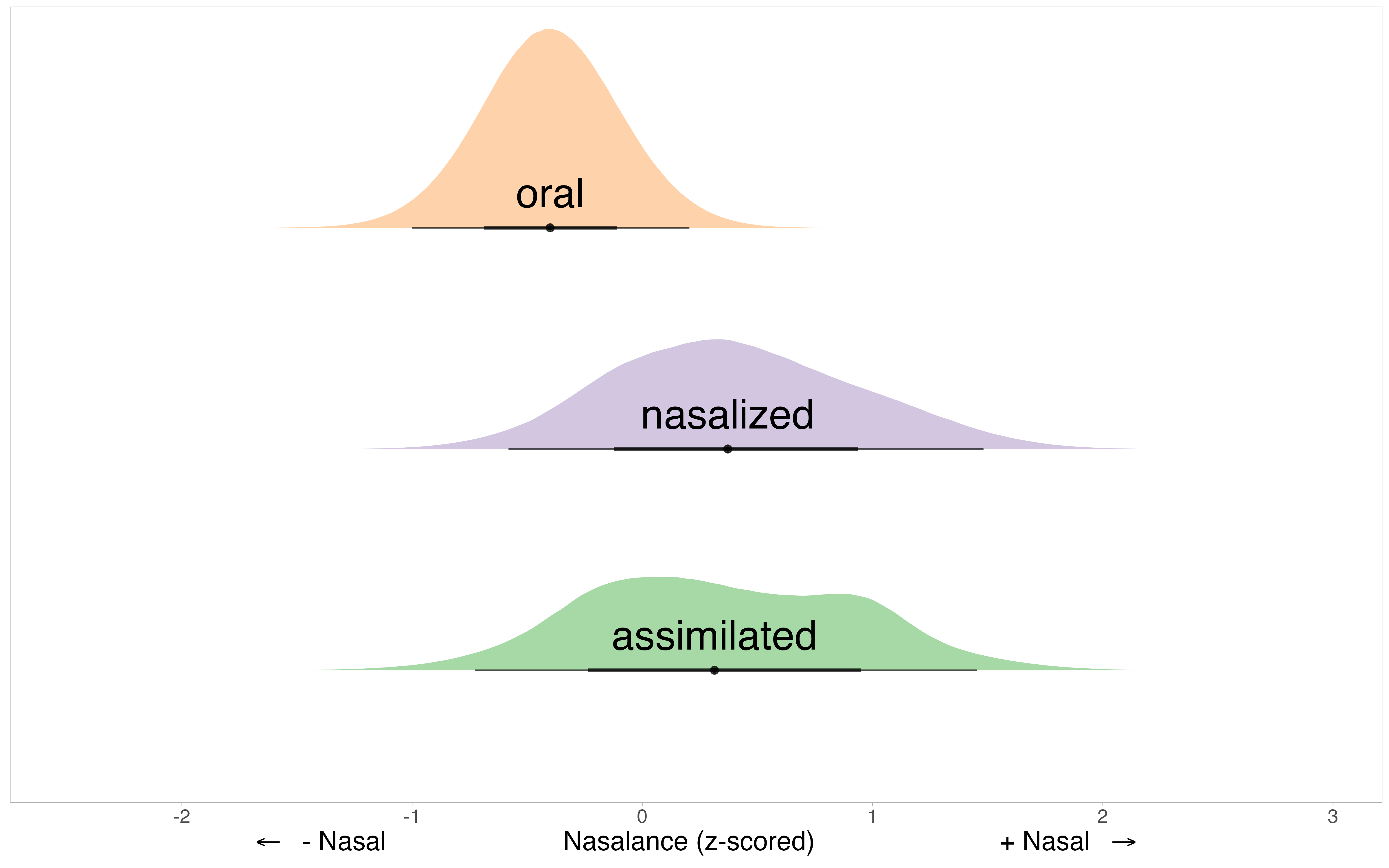
Posterior distributions
Contrast distribution of nasalized and oral posteriors

fPCA decomposes the shape of the curve
- Functional Principal Component Analysis summarizes numerically the main shape of variation in a functional dataset
In fPCA, the function of t approximates the mean of t plus the product of each PC score and its PC
Each given PC captures more variation than the following one
\(f(t) \approx \mu(t) + s_1 \times PC_1(t) + s_2 \times PC_2(t) + ...\)

fPCA allows to model and reconstruct the approximate shape of the curve
- We can recreate the approximate shape of a curve by adding the product of its PCs and their respective PC scores to the mean
\(f(t) \approx \mu(t) + s_1 \times PC_1(t) + s_2 \times PC_2(t) + ...\)

In our data, the first PC accounts for most of the variation

The variation accounted for by the first PC is vertical

Posterior distributions

Contrast distribution of the posteriors of nasal and oral PC scores

From estimated PC1 values back to our nasalance curves
